
What is Bulkhead Pattern?
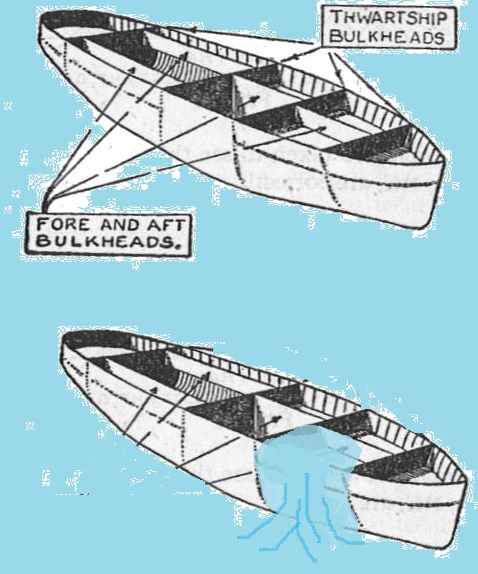
 Bulkheads in ships separate components or sections of a ship such that if one portion of a ship is breached, flooding can be contained to that section.
Bulkheads in ships separate components or sections of a ship such that if one portion of a ship is breached, flooding can be contained to that section.
Once contained, the ship can continue operations without risk of sinking.
In this fashion, ship bulkheads perform a similar function to physical building firewalls, where the firewall is meant to contain a fire to a specific section of the building.
The microservice bulkhead pattern is analogous to the bulkhead on a ship. The goal of the bulkhead pattern is to avoid faults in one part of a system to take the entire system down. By separating both functionality and data, failures in some component of a solution do not propagate to other components. This is most commonly employed to help scale what might be otherwise monolithic datastores.
What are the problems that can be fixed by Bulkhead Pattern?
The bulkhead pattern helps to fix a number of different quality of service related issues.
1). Propagation of Failure: Because solutions are contained and do not share resources (storage, synchronous service-to-service calls, etc), their associated failures are contained and do not propagate. When a service suffers a programmatic (software) or infrastructure failure, no other service is disrupted.
2). Noisy Neighbors: If implemented properly, network, storage and compute segmentation ensure that abnormally large resource utilization by a service does not affect other services outside of the bulkhead (fault isolation zone).
3). Unusual Demand: The bulkhead protects other resources from services experiencing unpredicted or unusual demand. Other resources do not suffer from TCP port saturation, resulting database deterioration, etc.
Principles to apply while using Bulkhead pattern
1). Share Nearly Nothing: As much as possible, services that are fault isolated or placed within a bulkhead should not share databases, firewalls, storage, load balancers, etc. Budgetary constraints may limit the application of unique infrastructure to these services. The following diagram helps explain what should never be shared, and what may be shared for cost purposes. The same principles apply, to the extent that they can be managed, within IaaS or PaaS implementations.
2). Avoid synchronous calls to other services: Service to service calls extend the failure domain of a bulkhead. Failures and slowness transit blocking synchronous calls and therefore violate the protection offered by a bulkhead.
When can we use the Bulkhead Pattern?
The default implementation of Hystrix’s thread pool contains ten threads for processing Hystrix wrapped calls. What would happen if the client is a heavy application with a high volume of Hystrix wrapped calls, which can be calls to a remote database or a service? The available threads will get exhausted in a short period of time and the client will fail.
What is the solution? Well, Hystrix provides the means to implement the bulkhead pattern and create separate thread pools for every remote resource call. If one resource call may be using all the available resources, only the associated thread pool is likely to fail, while other parts of the client remain intact.
The bulkhead implementation in Hystrix limits the number of concurrent calls to a particular component. This way, the number of resources (typically threads) that is waiting for a reply from the component is limited.
Assume you have a request based, multi threaded application that uses three different components, A, B, and C. If requests to component C starts to hang, eventually all request handling threads will hang on waiting for an answer from C. This would make the application entirely non-responsive. If requests to C is handled slowly we have a similar problem if the load is high enough.
Hystrix' implementation of the bulkhead pattern limits the number of concurrent calls to a component and would have saved the application in this case. Assume we have 30 request handling threads and there is a limit of 10 concurrent calls to C. Then at most 10 request handling threads can hang when calling C, the other 20 threads can still handle requests and use components A and B.
Hystrix' has two different approaches to the bulkhead, thread isolation and semaphore isolation.
Example to configure isolation:
Example of Bulkhead implementation in Hystrix
We defined a custom thread pool 'threadPoolDepartmentDetails' for the remote service call.
The threadPoolKey keyword defines a unique name for the thread pool.
coreSize is used to specify the size of the newly created thread pool. The default coreSize is ten.
maxQueueSize, is by default has a value of -1 and Hystrix blocks all incoming requests if no thread from the respective thread pool is available for processing. When the value is greater than 1, Hystrix uses a LinkedBlockingQueue to queue the requests until a thread becomes available for processing.
Beside the bulkhead pattern, the below example also includes the Circuit Breaker pattern. The fallback method fallbackGetDepartmentDetails which returns hard-coded results gets invoked every time the call to remote service fails or exceeds timeout. For the uninititaed, the fallback method SHOULD HAVE the exact same signature as the method wrapped by Hystrix.
What will happen if a Hystrix wrapped method (in our case getDepartmentDetails) continuously pings an unavailable, ailing, or resource-exhausted remote service? Does the fallback method (fallbackGetDepartmentDetails) gets continuously invoked?
To handle this Hystrix, besides providing means to implement circuit breaker and bulkhead patterns, offers a call monitoring functionality, that continuously monitors the number of times a wrapped method fails within a configurable ten-second window, and if a predefined call fail threshold is reached, the circuit breaker will be triggered and all following calls fail directly until the remote service is up and running.
We can add commandProperties to customize the default 'fail-fast' behaviour.
circuitBreaker.requestVolumeThreshold defines the number of consecutive calls that must happen within the ten-second window. If this number is reached, then the next property, circuitBreaker.errorThresholdPercentage, defines the percentage of the calls that need to fail in order the circuit breaker to be triggered.
After this, all the consecutive calls fail directly, without calling the unavailable service.
At some point, the application needs to check whether the remote service is available again or not? This is also handled by Hystrix and happens after a predefined timeout (which is by default ten seconds). This can be overridden by 'circuitBreaker.sleepWindowInMilliseconds'.
Download the code till now from below GIT url:
GIT URL: microservices
-K Himaanshu Shuklaa..
Once contained, the ship can continue operations without risk of sinking.
In this fashion, ship bulkheads perform a similar function to physical building firewalls, where the firewall is meant to contain a fire to a specific section of the building.
The microservice bulkhead pattern is analogous to the bulkhead on a ship. The goal of the bulkhead pattern is to avoid faults in one part of a system to take the entire system down. By separating both functionality and data, failures in some component of a solution do not propagate to other components. This is most commonly employed to help scale what might be otherwise monolithic datastores.
What are the problems that can be fixed by Bulkhead Pattern?
The bulkhead pattern helps to fix a number of different quality of service related issues.
1). Propagation of Failure: Because solutions are contained and do not share resources (storage, synchronous service-to-service calls, etc), their associated failures are contained and do not propagate. When a service suffers a programmatic (software) or infrastructure failure, no other service is disrupted.
2). Noisy Neighbors: If implemented properly, network, storage and compute segmentation ensure that abnormally large resource utilization by a service does not affect other services outside of the bulkhead (fault isolation zone).
3). Unusual Demand: The bulkhead protects other resources from services experiencing unpredicted or unusual demand. Other resources do not suffer from TCP port saturation, resulting database deterioration, etc.
Principles to apply while using Bulkhead pattern
1). Share Nearly Nothing: As much as possible, services that are fault isolated or placed within a bulkhead should not share databases, firewalls, storage, load balancers, etc. Budgetary constraints may limit the application of unique infrastructure to these services. The following diagram helps explain what should never be shared, and what may be shared for cost purposes. The same principles apply, to the extent that they can be managed, within IaaS or PaaS implementations.
2). Avoid synchronous calls to other services: Service to service calls extend the failure domain of a bulkhead. Failures and slowness transit blocking synchronous calls and therefore violate the protection offered by a bulkhead.
When can we use the Bulkhead Pattern?
- Apply the bulkhead pattern whenever you want to scale a service independent of other services.
- Apply the bulkhead pattern to fault isolate components of varying risk or availability requirements.
- Apply the bulkhead pattern to isolate geographies for the purposes of increased speed/reduced latency such that distant solutions do not share or communicate and thereby slow response times.
The default implementation of Hystrix’s thread pool contains ten threads for processing Hystrix wrapped calls. What would happen if the client is a heavy application with a high volume of Hystrix wrapped calls, which can be calls to a remote database or a service? The available threads will get exhausted in a short period of time and the client will fail.
What is the solution? Well, Hystrix provides the means to implement the bulkhead pattern and create separate thread pools for every remote resource call. If one resource call may be using all the available resources, only the associated thread pool is likely to fail, while other parts of the client remain intact.
The bulkhead implementation in Hystrix limits the number of concurrent calls to a particular component. This way, the number of resources (typically threads) that is waiting for a reply from the component is limited.
Assume you have a request based, multi threaded application that uses three different components, A, B, and C. If requests to component C starts to hang, eventually all request handling threads will hang on waiting for an answer from C. This would make the application entirely non-responsive. If requests to C is handled slowly we have a similar problem if the load is high enough.
Hystrix' implementation of the bulkhead pattern limits the number of concurrent calls to a component and would have saved the application in this case. Assume we have 30 request handling threads and there is a limit of 10 concurrent calls to C. Then at most 10 request handling threads can hang when calling C, the other 20 threads can still handle requests and use components A and B.
Hystrix' has two different approaches to the bulkhead, thread isolation and semaphore isolation.
- Thread Isolation: The standard approach is to hand over all requests to component C to a separate thread pool with a fixed number of threads and no (or a small) request queue.
- Semaphore Isolation: The other approach is to have all callers acquire a permit (with 0 timeout) before requests to C. If a permit can't be acquired from the semaphore, calls to C are not passed through.
Example to configure isolation:
Example of Bulkhead implementation in Hystrix
We defined a custom thread pool 'threadPoolDepartmentDetails' for the remote service call.
The threadPoolKey keyword defines a unique name for the thread pool.
coreSize is used to specify the size of the newly created thread pool. The default coreSize is ten.
maxQueueSize, is by default has a value of -1 and Hystrix blocks all incoming requests if no thread from the respective thread pool is available for processing. When the value is greater than 1, Hystrix uses a LinkedBlockingQueue to queue the requests until a thread becomes available for processing.
Beside the bulkhead pattern, the below example also includes the Circuit Breaker pattern. The fallback method fallbackGetDepartmentDetails which returns hard-coded results gets invoked every time the call to remote service fails or exceeds timeout. For the uninititaed, the fallback method SHOULD HAVE the exact same signature as the method wrapped by Hystrix.
What will happen if a Hystrix wrapped method (in our case getDepartmentDetails) continuously pings an unavailable, ailing, or resource-exhausted remote service? Does the fallback method (fallbackGetDepartmentDetails) gets continuously invoked?
To handle this Hystrix, besides providing means to implement circuit breaker and bulkhead patterns, offers a call monitoring functionality, that continuously monitors the number of times a wrapped method fails within a configurable ten-second window, and if a predefined call fail threshold is reached, the circuit breaker will be triggered and all following calls fail directly until the remote service is up and running.
We can add commandProperties to customize the default 'fail-fast' behaviour.
circuitBreaker.requestVolumeThreshold defines the number of consecutive calls that must happen within the ten-second window. If this number is reached, then the next property, circuitBreaker.errorThresholdPercentage, defines the percentage of the calls that need to fail in order the circuit breaker to be triggered.
After this, all the consecutive calls fail directly, without calling the unavailable service.
At some point, the application needs to check whether the remote service is available again or not? This is also handled by Hystrix and happens after a predefined timeout (which is by default ten seconds). This can be overridden by 'circuitBreaker.sleepWindowInMilliseconds'.
Download the code till now from below GIT url:
GIT URL: microservices
-K Himaanshu Shuklaa..
No comments:
Post a Comment