
The DAO layer usually consists of a lot of boilerplate code that can be simplified. Spring Data makes it possible to remove the DAO implementations entirely.
JPA (Java Persistent API) is the sun specification for persisting objects in the enterprise application. It is currently used as the replacement for complex entity beans.
To use Spring Data JPA for a JPA entity we declare a Java interface class that extends from CrudRepository.
org.springframework.data.repository.CrudRepository
where T is the domain type the repository manages and ID is the type of the ID of the entity the repository manages.
public interface EmployeeDAO extends CrudRepository {
Employee findByEmployeeName(String employeeName);
}
Extending CrudRepository enable Spring Data to find this interface and automatically create an implementation for it. By extending the interface we get the most relevant CRUD methods for standard data access available in a standard DAO.
CrudRepository Methods
a). Simply define a new method in the interface
b). Provide the actual JPQ query by using the @Query annotation
c). Use the more advanced Specification and Querydsl support in Spring Data
d). Define custom queries via JPA Named Queries
Automatic Custom Queries
When Spring Data creates a new Repository implementation, it analyses all the methods defined by the interfaces and tries to automatically generate queries from the method names. It's a very powerful and elegant way of defining new custom access methods with very little effort.
Let's say our entity has a field with a name 'employeeName'. If we want to fetch Employee based on name, we just need to define a method 'findByEmployeeName' in the DAO interface, this will automatically generate the correct query:
public interface EmployeeDAO extends CrudRepository {
Employee findByEmployeeName(String employeeName);
}
If you define a method (lets say findByEmpName), with invalid field name then below error message will be thrown:
java.lang.IllegalArgumentException: No property empName found for type class org.rest.model.Employee
Rules for Creating Query Methods
To write a simple query method, you need to follow below rules:

Supported keywords inside method names:


Manual Custom Queries: We can write a custom query, for this we need to use the @Query annotation:
public interface EmployeeDAO extends CrudRepository {
@Query("SELECT * FROM Employee e WHERE LOWER(e.employeeName) = LOWER(:employeeName)")
Employee retrieveByEmployeeName(@Param("name") String employeeName);
}
 Creating SQL Queries with @Query
Creating SQL Queries with @Query

@NamedQuery and @NamedQueries

Spring Data JPA @NamedNativeQuery and @NamedNativeQueries
Using stored procedures to implement parts of the application logic in the database is a widely used approach in huge, data-heavy applications. Nevertheless, there was no good support for them before JPA 2.1, because of which the developers had to use a native query, to call the stored procedure in the database.
Since the JPA 2.1 release, JPA supports two different ways to call stored procedures, the dynamic StoredProcedureQuery, and the declarative @NamedStoredProcedureQuery.Let's say we have created two Stored Procedures inside 'emp_test_pkg' in our SQL DB:
1. 'update_employee_flag': takes an input parameter(inParam1), but doesn't return a value.
2. 'get_employee_names' : takes an input parameter(inParam1), and returns a value(outParam1)
We can then call the stored procedures using the @NamedStoredProcedureQueries annotation. e.g
The key points are:

Parameter modes
There are 4 different modes of parameters to implement a stored procedure:
 Instead of repository We can also call the SP's by StoredProcedureQuery:
Instead of repository We can also call the SP's by StoredProcedureQuery:
StoredProcedureQuery query = this.em.createNamedStoredProcedureQuery("get_employee_names");
query.setParameter("inParam1", 1);
query.execute();
String sum = (String) query.getOutputParameterValue("outParam1");
How can we call a Stored Procedures with REF_CURSOR from Spring Data JPA?
Simple input and output parameters are often not enough, and the stored procedure returns the result of a query. In such case we need to use 'ParameterMode.REF_CURSOR' as mode in @StoredProcedureParameter.
In the following code snippet, we have used parameter mode as REF_CURSOR and positional parameter mapping instead of the name based one.

The usage of the query is also a little bit different. This time, we need to call getResultList() to get the result of the query. This method implicitly calls the execute() method (which is used to call the stored procedure in the database).

What is the difference between getOne and findById in Spring Data JPA?
Both findById() and getOne() methods are used to retrieve an object from underlying datastore. But the underlying mechanism for retrieving records is different for both these methods.
getOne():
The only real difference between getOne() and findById() is about the performance. Lazily loaded getOne() method avoids database roundtrip from the JVM as it never hits the database until the properties of returned proxy object are actually accessed.
There are scenarios when you just want to get retrieve an entity from database and assign it as a reference to another object, just to maintain the relationship (OneToOne or ManyToOne).
Differences:
 In the above example Employee object needs a reference of Department.
In the above example Employee object needs a reference of Department.
Let's create EmployeeRepository and DepartmentRepository, both will extends JpaRepository.
In HRService we are retrieving a reference of Department object and assigning it to employee. We are using getOne() instead of findById() in this particular case, because we need not to fetch the details of department object.
generated SQL traces in this case:
insert into t_employees (department_id, name, id) values (?, ?, ?)
When we use findById() instead of getOne(), then an additional call to database is made to retrieve the department object.
generated SQL traces: select department0_.id as id1_4_0_, department0_.name as name2_4_0_ from t_departments department0_ where department0_.id=?;
insert into t_employees (department_id, name, id) values (?, ?, ?);
We can see here that an additional call to database is made to eagerly fetch the department record, and then assign it as a reference in employee record.

What are the constraints on an entity class?
What are different states of an entity in persistence context?
There are 4 states of an Object in JPA: New (Transient), Persistent (Managed), Detached (Unmanaged) and Removed (deleted).
New (Transient): An object that is newly created and has never been associated with JPA Persistence Context (hibernate session) is considered to be in the New (Transient) state. The data of objects in this state is not stored in the database. e.g:
Student student = new Student("himanshu@scrutiny.com");
Persistent (JPA managed): An Object that is associated with persistence context (hibernate session) are in Persistent state. Any changes made to objects in this state are automatically propagated to databases without manually invoking persist/merge/remove.
Detached (unmanaged): An Object becomes detached when the currently running Persistence Context is closed. Any changes made to detached objects are no longer automatically propagated to the database.
Once tx.commit() is executed, the object becomes detached. If you make any changes in that object, it will not get updated in the database. We need to make use of merge to reattach the changes.
Removed : Removed objects are deleted from the database. JPA provides entityManager.remove(object); method to remove an entity from the database.
What is a JPA repository?
A JPA repository is a collection of methods for increasing program functionality. The most common repository for JPA is the Spring Data JPA that helps in decreasing the amount of boilerplate code.
What is Entity Manager in JPA?
What are inheritance mapping strategies in JPA?
JPA defines three inheritance strategies namely, SINGLE_TABLE, TABLE_PER_CLASS and JOINED.
Single Table Inheritance

We used single table inheritance in above example, only a single table will be created for both concrete classes (Android and IOS). Hibernate will create a discriminator column named DTYPE to differentiate each concrete type. The value of this column will be name of the entity (Android and IOS).
Table Per Class Inheritance
A table is defined for each concrete class in the inheritance hierarchy to store all the attribute of that class and all its super classes.
Joined Table

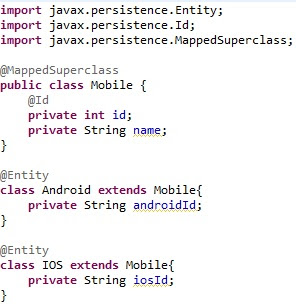
The above configuration will result in two tables for Android with 3 columns (id, name and androidId) and IOS with 3 columns (id, name and iosId). Mobile class will never have its own table in this case.
Explain One-to-One Relationship in JPA?
One-to-One Relationship Using a Foreign Key

In this case instead of creating a new column address_id, we'll mark the primary key column (user_id) of the Address table as the foreign key to the Users table.

Explain Many-To-Many Relationship in JPA.
Basic Many-To-Many
 Many-To-Many Using A Composite Key
Many-To-Many Using A Composite Key

A composite key class:

What are Transaction Isolation Levels? What is the difference between dirty reads, non-repeatable read and phantom read?
Transaction isolation levels are a measure of the extent to which transaction isolation succeeds. In particular, transaction isolation levels are defined by the presence or absence of the following phenomena:
Lost Update

Pessimistic Locking
No, JPA is only a specification. The ORM tools like Hibernate, iBatis, and TopLink implements the JPA specification and perform these type of tasks.
What is the object-relational mapping?
What are the steps to insert/persist, update, find and delete an entity?
What are the steps to insert/persist, update, find and delete an entity?
For insert/persist, update, find or delete, we need to perform below two steps:
Step 1). Create an entity class, e.g Student.java with the attribute student_name.

Step 2). Map the entity class and other databases configuration in Persistence.xml file.

To Insert an entity

To Find an entity

To Delete an entity
 To Update an entity via Transparent Update
To Update an entity via Transparent Update
Once an entity object is retrieved from the database (no matter which way) it can simply be modified in memory from inside an active transaction.
The entity object is physically updated in the database when the transaction is committed. If the transaction is rolled back and not committed the update is discarded.
 To Update an entity via UPDATE Queries
To Update an entity via UPDATE Queries
UPDATE queries provide an alternative way for updating entity objects in the database. Modifying objects using an UPDATE query may be useful especially when many entity objects have to be modified in one operation.
On success, the executeUpdate method returns the number of objects that have been modified by the query.

Apart from remove(), what are other different ways to Delete JPA entity objects from database?
1). Cascading Remove: Marking a reference field with CascadeType.REMOVE (or CascadeType.ALL, which includes REMOVE) indicates that remove operations should be cascaded automatically to entity objects that are referenced by that field (multiple entity objects can be referenced by a collection field).
e.g: Lets say we have Instructor and Course entities.
@Entity
@Table(name="instructor")
public class Instructor{
...
...
@OneToMany(mappedBy="instructor",
cascade= {CascadeType.REMOVE})
private List < Course > courses;
..
}
@Entity
@Table(name="course")
public class Course {
..
..
@ManyToOne(cascade=CascadeType.ALL)
@JoinColumn(name="instructor_id")
private Instructor instructor;
}
e.g:
@Entity
class Employee {
..
..
@OneToOne(orphanRemoval=true)
private Address address;
..
..
}
e.g: below query will delete all the employee instances:
int deletedCount = em.createQuery("DELETE FROM EMPLOYEES").executeUpdate();
1). find()
Student student = entityManager.find(Student.class, 1);
2). getReference()
Student student = entityManager.getReference(Student.class, 1);
3). Retrieval by Eager Fetch
@Entity
@Table(name="instructor")
public class Instructor {
..
..
@OneToMany(fetch=FetchType.LAZY, mappedBy="instructor",
cascade= {CascadeType.PERSIST, CascadeType.MERGE,
CascadeType.DETACH, CascadeType.REFRESH})
private List courses;
..
}
@Entity
@Table(name="course")
public class Course {
..
..
@ManyToOne(cascade=CascadeType.ALL)
@JoinColumn(name="instructor_id")
private Instructor instructor;
..
}
The most flexible method for retrieving objects from the database is to use queries.
e.g:
Query query = em.createQuery("SELECT e FROM EMPLOYEES e");
List results = query.getResultList();
TypedQuery < Long > query = em.createQuery(
"SELECT COUNT(e) FROM EMPLOYEES e", Long.class);
long countryCount = query.getSingleResult();
5). Retrieval by Refresh
class Employee {
..
..
@OneToOne(cascade=CascadeType.REFRESH)
private Address address;
..
}
-K Himaanshu Shuklaa..

JPA (Java Persistent API) is the sun specification for persisting objects in the enterprise application. It is currently used as the replacement for complex entity beans.
To use Spring Data JPA for a JPA entity we declare a Java interface class that extends from CrudRepository.
org.springframework.data.repository.CrudRepository
where T is the domain type the repository manages and ID is the type of the ID of the entity the repository manages.
public interface EmployeeDAO extends CrudRepository
Employee findByEmployeeName(String employeeName);
}
Extending CrudRepository enable Spring Data to find this interface and automatically create an implementation for it. By extending the interface we get the most relevant CRUD methods for standard data access available in a standard DAO.
CrudRepository Methods
- < S extends T > S save(S entity) : This saves a given entity. Use the returned instance for further operations as the save operation might have changed the entity instance completely.
- < S extends T > Iterable < S > saveAll(Iterable < S > entities) : Saves all given entities.
- Optional < T > findById(ID id) : Retrieves an entity by its id.
- boolean existsById(ID id) : Returns whether an entity with the given id exists.
- Iterable < T > findAll() : Returns all instances of the type.
- Iterable < T > findAllById(Iterable < ID > ids) : Returns all instances of the type {@code T} with the given IDs. If some or all ids are not found, no entities are returned for these IDs. Order of elements in the result is not guaranteed.
- long count() : Returns the number of entities available.
- void deleteById(ID id) : Deletes the entity with the given id.
- void delete(T entity) : Deletes a given entity.
- void deleteAll(Iterable < ? extends T > entities) : Deletes the given entities.
- void deleteAll() : Deletes all entities managed by the repository.
JpaRepository methods
- JpaRepository < T, ID > extends both PagingAndSortingRepository < T, ID > and QueryByExampleExecutor < T >
- List < T > findAll();
- List < T > findAll(Sort sort);
- List < T > findAllById(Iterable < ID > ids);
- < S extends T > List < S > saveAll(Iterable < S > entities);
- void flush() : Flushes all pending changes to the database
- < S extends T > S saveAndFlush(S entity) : Saves an entity and flushes changes instantly
- void deleteInBatch(Iterable < T > entities) : Deletes the given entities in a batch which means it will create a single {@link Query}. Assume that we will clear the {@link javax.persistence.EntityManager} after the call.
- void deleteAllInBatch() : Deletes all entities in a batch call.
- T getOne(ID id) : Returns a reference to the entity with the given identifier. Depending on how the JPA persistence provider is implemented this is very likely to always return an instance and throw an {@link javax.persistence.EntityNotFoundException} on first access. Some of them will reject invalid identifiers immediately.
- < S extends T > List < S > findAll(Example < S > example);
- < S extends T > List < S > findAll(Example < S > example, Sort sort);
Custom Access Method and Queries
To define our own custom methods for specific use, we need to:a). Simply define a new method in the interface
b). Provide the actual JPQ query by using the @Query annotation
c). Use the more advanced Specification and Querydsl support in Spring Data
d). Define custom queries via JPA Named Queries
Automatic Custom Queries
When Spring Data creates a new Repository implementation, it analyses all the methods defined by the interfaces and tries to automatically generate queries from the method names. It's a very powerful and elegant way of defining new custom access methods with very little effort.
Let's say our entity has a field with a name 'employeeName'. If we want to fetch Employee based on name, we just need to define a method 'findByEmployeeName' in the DAO interface, this will automatically generate the correct query:
public interface EmployeeDAO extends CrudRepository
Employee findByEmployeeName(String employeeName);
}
If you define a method (lets say findByEmpName), with invalid field name then below error message will be thrown:
java.lang.IllegalArgumentException: No property empName found for type class org.rest.model.Employee
Rules for Creating Query Methods
To write a simple query method, you need to follow below rules:
- mention the correct return type
- begin the signature with 'findBy', which will be followed by an attribute name in camel case.
- If we want to limit the number of returned query results, we can add the First or the Top keyword before the first By word. If we want to get more than one result, we have to append the optional numeric value to the First and the Top keywords. For example, findTopBy, findTop1By, findFirstBy, and findFirst1By all return the first entity that matches the specified search criteria.
- If we want to select unique results, we have to add the Distinct keyword before the first By word. For example, findTitleDistinctBy or findDistinctTitleBy means that we want to select all unique titles that are found from the database.

Supported keywords inside method names:


Manual Custom Queries: We can write a custom query, for this we need to use the @Query annotation:
public interface EmployeeDAO extends CrudRepository
@Query("SELECT * FROM Employee e WHERE LOWER(e.employeeName) = LOWER(:employeeName)")
Employee retrieveByEmployeeName(@Param("name") String employeeName);
}

- The @Query annotation allows for running native queries by setting the nativeQuery flag to true. Below steps need to be followed to create a SQL query with the @Query annotation:
- Add a query method to our repository interface.
- Annotate the query method with the @Query annotation, and specify the invoked query by setting it as the value of the @Query annotation’s value attribute.
- Set the value of the @Query annotation’s nativeQuery attribute to true.

@NamedQuery and @NamedQueries
- @NamedQuery annotation is a predefined query that we create and associate with a container-managed entity.
- @Query annotation is a similar annotation, which declares finder queries directly on repository methods. While @NamedQuery is used on domain classes, Spring Data JPA @Query annotation is used on Repository interface.
- @NamedQueries specifies multiple named Java Persistence query language queries. Query names are scoped to the persistence unit.
- Both @NamedQuery and @NamedQueries annotation can be applied to an entity or mapped superclass.

Spring Data JPA @NamedNativeQuery and @NamedNativeQueries
- @NamedNativeQuery and @NamedNativeQueries annotations let you define the query in native SQL by losing the database platform independence.
- Both annotations can be applied to an entity or mapped superclass.
Using stored procedures to implement parts of the application logic in the database is a widely used approach in huge, data-heavy applications. Nevertheless, there was no good support for them before JPA 2.1, because of which the developers had to use a native query, to call the stored procedure in the database.
Since the JPA 2.1 release, JPA supports two different ways to call stored procedures, the dynamic StoredProcedureQuery, and the declarative @NamedStoredProcedureQuery.Let's say we have created two Stored Procedures inside 'emp_test_pkg' in our SQL DB:
1. 'update_employee_flag': takes an input parameter(inParam1), but doesn't return a value.
2. 'get_employee_names' : takes an input parameter(inParam1), and returns a value(outParam1)
We can then call the stored procedures using the @NamedStoredProcedureQueries annotation. e.g
The key points are:
- The Stored Procedure uses the annotation @NamedStoredProcedureQuery and is bound to a JPA table.
- procedureName: It contains the package name followed by the name of the stored procedure.
- name: It is the name of the StoredProcedure in the JPA ecosystem.
- IN/OUT parameter are defined using ParameterMode

Parameter modes
There are 4 different modes of parameters to implement a stored procedure:
- IN: for input parameters,
- OUT: for output parameters,
- INOUT: for parameters which are used for input and output and
- REF_CURSOR: for cursors on a result set.
- Now we will create the Spring Data JPA repository.
- @Procedure: the name parameter must match the name on @NamedStoredProcedureQuery
- @Param: Must match @StoredProcedureParameter name parameter
- Return types must match - so updateEmployeeFlag is void, and getEmployeeName returns String
 Instead of repository We can also call the SP's by StoredProcedureQuery:
Instead of repository We can also call the SP's by StoredProcedureQuery:StoredProcedureQuery query = this.em.createNamedStoredProcedureQuery("get_employee_names");
query.setParameter("inParam1", 1);
query.execute();
String sum = (String) query.getOutputParameterValue("outParam1");
How can we call a Stored Procedures with REF_CURSOR from Spring Data JPA?
Simple input and output parameters are often not enough, and the stored procedure returns the result of a query. In such case we need to use 'ParameterMode.REF_CURSOR' as mode in @StoredProcedureParameter.
In the following code snippet, we have used parameter mode as REF_CURSOR and positional parameter mapping instead of the name based one.

The usage of the query is also a little bit different. This time, we need to call getResultList() to get the result of the query. This method implicitly calls the execute() method (which is used to call the stored procedure in the database).

What is the difference between getOne and findById in Spring Data JPA?
Both findById() and getOne() methods are used to retrieve an object from underlying datastore. But the underlying mechanism for retrieving records is different for both these methods.
getOne():
- getOne() returns a reference to the entity with the given identifier.
- It internally invokes EntityManager.getReference() method.
- getOne() method will always return a proxy without hitting the database (lazily fetched).
- This method will throw EntityNotFoundException at the time of actual access if the requested entity does not exist in the database.
- This method will actually hit the database and return the real object mapping to a row in the database.
- It is eager loaded operation that returns null, if no record exists in database.
The only real difference between getOne() and findById() is about the performance. Lazily loaded getOne() method avoids database roundtrip from the JVM as it never hits the database until the properties of returned proxy object are actually accessed.
There are scenarios when you just want to get retrieve an entity from database and assign it as a reference to another object, just to maintain the relationship (OneToOne or ManyToOne).
Differences:
- getOne() lazily load reference to target entity, where as findById() actually loads the entity for the given id
- getOne() is useful only when access to properties of object is not required. When object is eagerly loaded so all attributes can be accessed, findById() is used.
- getOne() throws EntityNotFoundException if actual object does not exist at the time of access invocation. findById() returns null if actual object corresponding to given Id does not exist
- getOne() has better performance. But findById() performance is low because an additional round-trip to database is required

Let's create EmployeeRepository and DepartmentRepository, both will extends JpaRepository.
In HRService we are retrieving a reference of Department object and assigning it to employee. We are using getOne() instead of findById() in this particular case, because we need not to fetch the details of department object.
generated SQL traces in this case:
insert into t_employees (department_id, name, id) values (?, ?, ?)
When we use findById() instead of getOne(), then an additional call to database is made to retrieve the department object.
generated SQL traces: select department0_.id as id1_4_0_, department0_.name as name2_4_0_ from t_departments department0_ where department0_.id=?;
insert into t_employees (department_id, name, id) values (?, ?, ?);
We can see here that an additional call to database is made to eagerly fetch the department record, and then assign it as a reference in employee record.

What are the constraints on an entity class?
- The class must be annotated with the javax.persistence.Entity annotation.
- The class must have a public or protected, no-argument constructor. The class may have other constructors.
- The class can't be final. No methods or persistent instance variables must be declared final.
- If an entity instance is passed by value as a detached object, such as through a session bean's remote business interface, the class must implement the Serializable interface.
- Entities may extend both entity and non-entity classes, and non-entity classes may extend entity classes.
- Persistent instance variables must be declared private, protected, or package-private and can be accessed directly only by the entity class's methods. Clients must access the entity's state through accessors or business methods.
There are 4 states of an Object in JPA: New (Transient), Persistent (Managed), Detached (Unmanaged) and Removed (deleted).
New (Transient): An object that is newly created and has never been associated with JPA Persistence Context (hibernate session) is considered to be in the New (Transient) state. The data of objects in this state is not stored in the database. e.g:
Student student = new Student("himanshu@scrutiny.com");
Persistent (JPA managed): An Object that is associated with persistence context (hibernate session) are in Persistent state. Any changes made to objects in this state are automatically propagated to databases without manually invoking persist/merge/remove.
Detached (unmanaged): An Object becomes detached when the currently running Persistence Context is closed. Any changes made to detached objects are no longer automatically propagated to the database.
Once tx.commit() is executed, the object becomes detached. If you make any changes in that object, it will not get updated in the database. We need to make use of merge to reattach the changes.
Removed : Removed objects are deleted from the database. JPA provides entityManager.remove(object); method to remove an entity from the database.
What is a JPA repository?
A JPA repository is a collection of methods for increasing program functionality. The most common repository for JPA is the Spring Data JPA that helps in decreasing the amount of boilerplate code.
What is Entity Manager in JPA?
- JPA EntityManager is used by developers to access a specific application database.
- Entitymanager is also used to tackle persistent instances of entities, to use primary key identity to locate other entities and to perform queries over different entities.
- The entity manager implements the API and encapsulates all of them within a single interface.
- The entity manager is used to read, delete and write an entity.
- An object referenced by an entity is managed by entity manager.
Pagination is the process of displaying or returning a specific number of pages among a huge dataset, which can be a subset of the data. This is usually applied when a small portion of the data has to be displayed to the user, like on a web page of an online store.
How to save UUIDs using JPA?
- UUIDs are used for copying and transferring records from one place to another and to regenerate keys.
- In JPA, the most common way to use primary keys is through the GeneratedValue annotation where the strategy attribute is set to TABLE, SEQUENCE, AUTO, and IDENTITY.
What is a JPA provider?
In JPA, there are no implementation classes only a set of interfaces. A JPA provider helps in this regard to implement the specifications. The most popular JPA providers are EclipseLink and Hibernate.
What is JPA remove?
- To delete an object from a database, at first it has to be retrieved. It can then deleted using the remove() method in an active transaction. In this case, the object is deleted from the database when the transaction occurs. This method is called explicit remove.
- Other methods for removing objects are cascading remove, using DELETE queries and Orphan Removal method.
JPA defines three inheritance strategies namely, SINGLE_TABLE, TABLE_PER_CLASS and JOINED.
Single Table Inheritance
- A single table is used to store all the instances of the entire inheritance hierarchy.
- The Table will have a column for every attribute of every class in the hierarchy.
- Discriminator columns identifies which class a particular row belongs.

We used single table inheritance in above example, only a single table will be created for both concrete classes (Android and IOS). Hibernate will create a discriminator column named DTYPE to differentiate each concrete type. The value of this column will be name of the entity (Android and IOS).
Table Per Class Inheritance
A table is defined for each concrete class in the inheritance hierarchy to store all the attribute of that class and all its super classes.
Joined Table
- Joined Table inheritance replicates the object model into data model.
- A table is created for each class in the hierarchy to store only the local attributes of that class.

- The above example three tables will be created, one for super class Mobile and two for entity Android and IOS. All the tables will have id identifier column.
- The primary key of tables IOS or Android will have foreign key relationship with primary key of Mobile table.
- If we create a normal class as the super class, then as per JPA specifications, the fields for that class are not persisted in the database tables.
- For this we need to create a super class extracting the common fields and then annotate that class with @MappedSuperClass in order to persist the fields of that super class in subclass tables.
- A mapped super class has no separate table defined for it.

The above configuration will result in two tables for Android with 3 columns (id, name and androidId) and IOS with 3 columns (id, name and iosId). Mobile class will never have its own table in this case.
Explain One-to-One Relationship in JPA?
One-to-One Relationship Using a Foreign Key
- Let's understand by taking an example, suppose we are building a User Management System, in which we need to maintain the relationship between User and its address. And as per the requirement one user will have one mailing address, and a mailing address will have only one user tied to it.
- For this we will two tables User and Address, and the address_id column in User table is the foreign key to Address.

- Inside the User entity, we declared Address with @OneToOne annotation.
- @JoinColumn annotation to configure the name of the column in the users table that maps to the primary key in the address table. If we don't provide a name, then Hibernate will follow some rules to select a default one.
- In the Address entity, we used @OneToOne annotation because this is a bidirectional relationship. The address side of the relationship is called the non-owning side.
- In Address Entity we have not added @JoinColumn because we only need it on the owning side of the foreign key relationship. Simply whoever owns the foreign key column gets the @JoinColumn annotation.
In this case instead of creating a new column address_id, we'll mark the primary key column (user_id) of the Address table as the foreign key to the Users table.

- @MapsId tells Hibernate to use the id column of Address as both primary key and foreign key. That's why the @Id column of the Address entity no longer uses the @GeneratedValue annotation.
- Also, mappedBy attribute is now moved to the User class since the foreign key is now present in the address table.
- One-to-one mappings can be of two types: Optional and Mandatory.
- One-to-One Relationship Using a Foreign Key or Shared Primary Key are mandatory relationships.
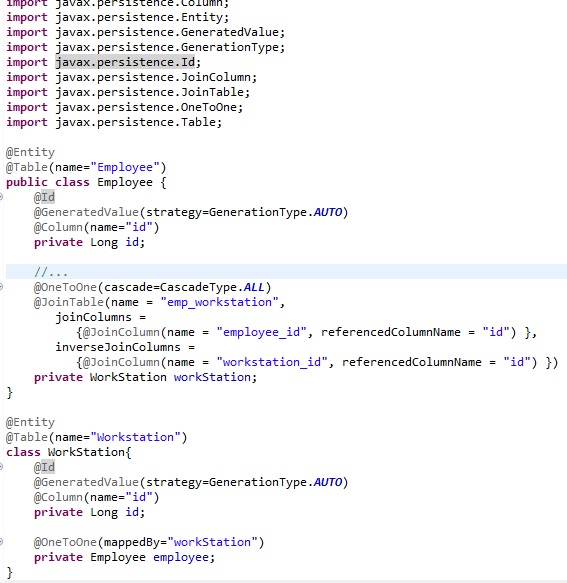
- Usually, we think of many-to-many relationships when we consider a join table, but, using a join table in One-to-One Relationship can help us to eliminate these null values.
- We have to maintain employee list and the workstation associated with that employee. It's one-to-one, but sometimes an employee might not have a workstation and vice-versa.
- We will create three tables: Employee (columns: id, name etc), Workstation(columns: id, workstation_no, floor etc) and Emp_WS_Mapping(columns: employee_id, workstation_id).
- Now, whenever we have a relationship, we'll make an entry in the emp_workstation table and avoid nulls altogether.
- @JoinTable instructs Hibernate to employ the join table strategy while maintaining the relationship. Also, Employee is the owner of this relationship as we chose to use the join table annotation on it.

Explain Many-To-Many Relationship in JPA.
Basic Many-To-Many
- In case of a many-to-many relationship, both sides can relate to multiple instances of the other side.
- It's possible for entity types to be in a relationship with themselves. e.g when we model organization relationships, every node is a Employee, so if we talk about the subordinate-manager relationship, both participants will be a Employee.
- The students mark the courses they like.
- Here a student can like many courses, and many students can like the same course.
- We will create three tables: Students, Course and stu_course_mapping.
- stu_course_mapping is called a join table. It is the combination of the foreign keys will be its composite primary key.
- We created two entities Student and Course, included a Collection in both classes, which contains the elements of the others.
- After that, we need to mark the class with @Entity, and the primary key with @Id to make them proper JPA entities and mark the collections with @ManyToMany annotations.
- We have to configure how to model the relationship in the RDBMS. The owner side is where we configure the relationship (in our case its Student entity). We can do this with the @JoinTable annotation in the Student class. We provide the name of the join table (stu_course_mapping), and the foreign keys with the @JoinColumn annotations. The joinColumn attribute will connect to the owner side of the relationship, and the inverseJoinColumn to the other side.
- FYI, @JoinTable and @JoinColumn isn't required. JPA will generate the table and column names for us. However, the strategy JPA uses won't always match the naming conventions we use. Hence the possibility to configure table and column names.
- On the target side, we only have to provide the name of the field, which maps the relationship. Therefore, we set the mappedBy attribute of the @ManyToMany annotation in the Course class.
- Since a many-to-many relationship doesn't have an owner side in the database, we could configure the join table in the Course class and reference it from the Student class.

- Now let's say we want to let students rate the courses.
- A student can rate any number of courses, and any number of students can rate the same course. Therefore, it's also a many-to-many relationship.
- Here we also need to store the rating score the student gave on the course.
- We need to create a Student and Course table. We will store the ratings in a mapping table course_rating, we will attach a new attribute to the join table to store the rating given by student.
- While declaring many-to-many relationship the entity, we cannot add a property. Therefore, we had no way to add a property to the relationship itself.
- Since we map DB attributes to class fields in JPA, we need to create a new entity class for the relationship. Every JPA entity needs a primary key. Because our primary key is a composite key, we have to create a new class CourseRatingKey, which will hold the different parts of the key.

A composite key class:
- Should be marked with @Embeddable
- It has to implement java.io.Serializable
- We need to provide an implementation of the hashcode() and equals() methods
- None of the fields can be an entity themselves.

- We used @EmbeddedId, to mark the primary key, which is an instance of the CourseRatingKey class. We marked the student and course fields with @MapsId. @MapsId is used to tie those fields to a part of the key, and they're the foreign keys of a many-to-one relationship. We need it, because in the composite key we can't have entities.
- After this, we can configure the inverse references in the Student and Course entities.
What is an orphan removal in mappings?
If a target entity in one-to-one or one-to-many mapping is removed from the mapping, then remove operation can be cascaded to the target entity. Such target entities are known as orphans, and the orphanRemoval attribute can be used to specify that orphaned entities should be removed.
Transaction isolation levels are a measure of the extent to which transaction isolation succeeds. In particular, transaction isolation levels are defined by the presence or absence of the following phenomena:
- A Dirty read is the situation when a transaction reads a data that has not yet been committed. For example, Let’s say transaction 1 updates a row and leaves it uncommitted, meanwhile, Transaction 2 reads the updated row. If transaction 1 rolls back the change, transaction 2 will have read data that is considered never to have existed.
- Non Repeatable read occurs when a transaction reads same row twice, and get a different value each time. For example, suppose transaction T1 reads data. Due to concurrency, another transaction T2 updates the same data and commit, Now if transaction T1 rereads the same data, it will retrieve a different value.
- Phantom Read occurs when two same queries are executed, but the rows retrieved by the two, are different. For example, suppose transaction T1 retrieves a set of rows that satisfy some search criteria. Now, Transaction T2 generates some new rows that match the search criteria for transaction T1. If transaction T1 re-executes the statement that reads the rows, it gets a different set of rows this time.
- ransaction isolation level Dirty reads Nonrepeatable reads Phantoms
- Read uncommitted: Dirty reads, Nonrepeatable reads and Phantoms read occurs.
- Read committed: Nonrepeatable reads and Phantoms read occurs.
- Repeatable read: Only Phantoms read occurs
- Serializable: Neither Dirty reads, Nonrepeatable reads or Phantoms read occurs.
- @Transactional annotation is used to wrap a method in a database transaction.
- It allows us to set propagation, isolation, timeout, read-only, and rollback conditions for our transaction.
- We can put the @Transactional annotation on definitions of interfaces, classes, or directly on methods. They override each other according to the priority order. From lowest to highest we have: interface, superclass, class, interface method, superclass method, and class method.
- It is not recommended to set the @Transactional on the interface. However, it is acceptable for cases like @Repository with Spring Data.
- If we annotate a class with @Transactional, Spring will apply this annotation to all public methods of this class that we did not annotate with @Transactional. However, if we put the annotation on a private or protected method, Spring will ignore it without an error.
- Spring manages to start and pause a transaction according to our propagation setting. Transaction Propagation defines our business logic‘s transaction boundary.
- Spring calls TransactionManager::getTransaction to get or create a transaction according to the propagation.
- REQUIRED Propagation: It is the default propagation. Spring checks if there is an active transaction, then it creates a new one if nothing existed. Otherwise, the business logic appends to the currently active transaction.
- SUPPORTS Propagation: If we use this propagation, Spring first checks if an active transaction exists. If a transaction exists, then the existing transaction will be used. If there isn't a transaction, it is executed non-transactional.
- MANDATORY Propagation: If there is an active transaction, then it will be used. If there isn't an active transaction, then Spring throws an exception.
- NEVER Propagation: Spring throws an exception if there's an active transaction.
- NOT_SUPPORTED Propagation: Spring at first suspends the current transaction if it exists, then the business logic is executed without a transaction.
- REQUIRES_NEW Propagation: Spring suspends the current transaction if it exists and then creates a new one.
- NESTED Propagation: Spring checks if a transaction exists, then if yes, it marks a savepoint. This means if our business logic execution throws an exception, then transaction rollbacks to this savepoint. If there's no active transaction, it works like REQUIRED. DataSourceTransactionManager supports this propagation out-of-the-box. Also, some implementations of JTATransactionManager may support this. JpaTransactionManager supports NESTED only for JDBC connections. However, if we set nestedTransactionAllowed flag to true, it also works for JDBC access code in JPA transactions if our JDBC driver supports savepoints.
Lost Update
- When two concurrent transactions simultaneously updating the same database record/column, which resulys in first update being silently overwritten by the second transaction. This phenomenon in Database is known as classic problem of Lost Updates.
- There are mainly two approaches to handle such scenarios: Optimistic and Pessimistic locking/
- When we are using optimistic locking, all users/threads can read the data concurrently.
- When more than one thread tries to update the same record/column simultaneously, the first one will win and all others will fail with OptimisticLockException, they have to try executing the update once again. Because of this no update will be silently lost even in case of concurrent usage.
- Each record in database maintains a version number. When first transaction reads record from DB, it would receive the version too. While updating the record/column the server compares the record’s version number with that in the database, and if not changed, then record is updated and version number is incremented.
- Now when a second transaction comes to update the same record/column and has previous version number, the server would recognize that the version number has changed in the database by first transaction, and reject the update.
- JPA Optimistic locking allows everone to read and update an entity, however performs a version check is when the transaction is committed. It will throw an exception if the version was updated in the database since the entity was last read.
- The advantages of optimistic locking are that no database locks are held which can give better scalability.
- The disadvantages are that the user or application must refresh and retry failed updates.
- To enable Optimistic Locking for an entity in JPA, we just have to annotate an attribute with @Version.
- Only short, int, long and Timestamp fields can be annotated with @Version attributes.We need to keep in mind that Timestamps are a less reliable way of optimistic locking than version numbers, but can be used by applications for other purposes as well.

Pessimistic Locking
- In case of pessimistic locking, hibernate locks the record for our exclusive use until you commit the transaction.
- This is typically achieved by using 'SELECT ___ FOR UPDATE' statement at the database level. When we do this any other transaction trying to update/access the same record will be blocked until the first transaction releases the lock.
- This gives better predictability at the price of performance and does not scale much.
- To enable pessimistic locking, we need to specify the appropriate Isolation Level at the transaction level. LockMode can be used to obtain a pessimistic lock in hibernate session.
- LockMode.UPGRADE: acquired upon explicit user request using SELECT … FOR UPDATE on databases which support that syntax.
- LockMode.UPGRADE_NOWAIT: acquired upon explicit user request using a SELECT … FOR UPDATE NOWAIT in Oracle.
- Isolation Levels affect what you see.
- Lock Modes affect what you are allowed to do.
No, JPA is only a specification. The ORM tools like Hibernate, iBatis, and TopLink implements the JPA specification and perform these type of tasks.
What is the object-relational mapping?
- The ORM or object-relational mapping is a mechanism which is used to develop and maintain a relationship between an object and the relational database by mapping an object state into the database column.
- ORM mapping converts attributes of programming code into columns of the table.
- It is capable of handling various database operations easily such as insertion, updation, deletion, etc.
- JPQL is Java Persistence Query Language defined in JPA specification.
- JPQL is developed based on SQL syntax. But it won’t affect the database directly.
- It is used to create queries against entities to store in a relational database.
- JPQL can retrieve information or data using SELECT clause, can do bulk updates using UPDATE clause and remove by using DELETE clause. EntityManager.createQuery() API will support for querying language.
For insert/persist, update, find or delete, we need to perform below two steps:
Step 1). Create an entity class, e.g Student.java with the attribute student_name.

Step 2). Map the entity class and other databases configuration in Persistence.xml file.
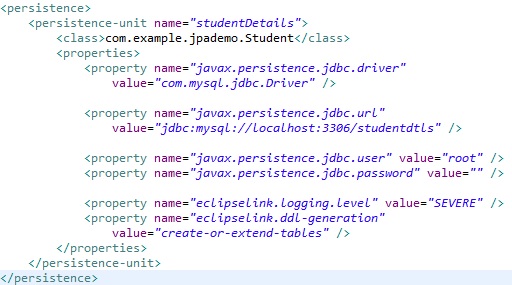
To Insert an entity

To Find an entity

To Delete an entity

Once an entity object is retrieved from the database (no matter which way) it can simply be modified in memory from inside an active transaction.
The entity object is physically updated in the database when the transaction is committed. If the transaction is rolled back and not committed the update is discarded.
UPDATE queries provide an alternative way for updating entity objects in the database. Modifying objects using an UPDATE query may be useful especially when many entity objects have to be modified in one operation.
On success, the executeUpdate method returns the number of objects that have been modified by the query.

Apart from remove(), what are other different ways to Delete JPA entity objects from database?
1). Cascading Remove: Marking a reference field with CascadeType.REMOVE (or CascadeType.ALL, which includes REMOVE) indicates that remove operations should be cascaded automatically to entity objects that are referenced by that field (multiple entity objects can be referenced by a collection field).
e.g: Lets say we have Instructor and Course entities.
@Entity
@Table(name="instructor")
public class Instructor{
...
...
@OneToMany(mappedBy="instructor",
cascade= {CascadeType.REMOVE})
private List < Course > courses;
..
}
@Entity
@Table(name="course")
public class Course {
..
..
@ManyToOne(cascade=CascadeType.ALL)
@JoinColumn(name="instructor_id")
private Instructor instructor;
}
- The Instructor entity class contains a courses field that references an instance of Course, which is another entity class.
- Due to the CascadeType.REMOVE setting, when an Instructor instance is removed the operation is automatically cascaded to the referenced Course instances, which is then automatically removed as well. Cascading may continue recursively when applicable (e.g. to entity objects that the Course object references, if any).
e.g:
@Entity
class Employee {
..
..
@OneToOne(orphanRemoval=true)
private Address address;
..
..
}
- In the above example, when an Employee entity object is removed the remove operation is cascaded to the referenced Address entity object. In this regard, orphanRemoval=true and cascade=CascadeType.REMOVE are identical, and if orphanRemoval=true is specified, CascadeType.REMOVE is redundant.
- Orphan removal can also be set for collection and map fields.
e.g: below query will delete all the employee instances:
int deletedCount = em.createQuery("DELETE FROM EMPLOYEES").executeUpdate();
- A TransactionRequiredException is thrown if no transaction is active.
- On success, the executeUpdate method returns the number of objects that have been deleted by the query.
1). find()
- Every entity object can be uniquely identified and retrieved by the combination of its class and its primary key by using find() method of entityManager.
- The casting of the retrieved object to Student is not required because find is defined as returning an instance of the same class that it takes as a first argument (using generics).
- An IllegalArgumentException is thrown if the specified class is not an entity class.
Student student = entityManager.find(Student.class, 1);
2). getReference()
- getReference() can be considered the lazy version of find().
- The getReference() method works like the find method except that, if the entity object is not already managed by the EntityManager a hollow object might be returned (null is never returned).
- A hollow object is initialized with the valid primary key but all its other persistent fields are uninitialized.
Student student = entityManager.getReference(Student.class, 1);
3). Retrieval by Eager Fetch
- Retrieval of an entity object from the database might cause automatic retrieval of additional entity objects.
- The default fetch policy of persistent collection and map fields is FetchType.LAZY. Therefore, by default, when an entity object is retrieved any other entity objects that it references through its collection and map fields are not retrieved with it.
@Entity
@Table(name="instructor")
public class Instructor {
..
..
@OneToMany(fetch=FetchType.LAZY, mappedBy="instructor",
cascade= {CascadeType.PERSIST, CascadeType.MERGE,
CascadeType.DETACH, CascadeType.REFRESH})
private List
..
}
@Entity
@Table(name="course")
public class Course {
..
..
@ManyToOne(cascade=CascadeType.ALL)
@JoinColumn(name="instructor_id")
private Instructor instructor;
..
}
- When we specify FetchType.EAGER explicitly in @OneToMany or @ManyToMany annotations enables cascading retrieval for the field.
- In the above example, if we mention FetchType.EAGER when an Instructor instance is retrieved all the referenced Courses instances are also retrieved automatically.
The most flexible method for retrieving objects from the database is to use queries.
e.g:
Query query = em.createQuery("SELECT e FROM EMPLOYEES e");
List results = query.getResultList();
TypedQuery < Long > query = em.createQuery(
"SELECT COUNT(e) FROM EMPLOYEES e", Long.class);
long countryCount = query.getSingleResult();
5). Retrieval by Refresh
- Managed objects can be reloaded from the database by using the refresh method. e.g: entityManager.refresh(student);
- The content of the managed object in memory is discarded (including changes, if any) and replaced by data that is retrieved from the database. This might be useful to ensure that the application deals with the most up to date version of an entity object, just in case it might have been changed by another EntityManager since it was retrieved.
- An IllegalArgumentException is thrown by refresh if the argument is not a managed entity (including entity objects in the New, Removed or Detached states). If the object does not exist in the database anymore an EntityNotFoundException is thrown.
- Marking a reference field with CascadeType.REFRESH (or CascadeType.ALL, which includes REFRESH) indicates that refresh operations should be cascaded automatically to entity objects that are referenced by that field (multiple entity objects can be referenced by a collection field).
class Employee {
..
..
@OneToOne(cascade=CascadeType.REFRESH)
private Address address;
..
}
-K Himaanshu Shuklaa..
No comments:
Post a Comment